What is a transaction?
A way to group multiple reads and writes into a single unit. This ensures that the entire transaction is completed in that case it’s committed. If any of the operations fail, the whole transaction is rolled back. This ensures that no partial updates exist. Like anything, transactions have advantages and disadvantages, let’s first look at the safety guarantees they provide.
ACID Properties
- Atomicity: This is the ability to ensure that either all operations in a transaction are completed or none are. This ensures that the database is always in a consistent state. If any operation fails, the entire transaction is rolled back.
- Consistency: I like how Martin mentions in this section that firstly the word is overloaded and secondly that it’s not a property of the database but of the application. In a transaction any writes done preserve the validity, ensuring that the invariants are always satisfied. Hence it’s the responsibility to define transactions correctly to preserve consistency.
- Isolation: From the book - “Concurrently executing transactions are isolated from each other: they cannot step on each other’s toes.” Here come various isolation levels strongest being “serializability” basically meaning one transaction can only run at a time(access to that data). In practice, serializable isolation is rarely used. Will touch upon other weaker isolation levels in a separate section.
- Durability: Once a transaction is committed, any data it has written will not be lost. Even if there is hardware or the database crashes. So data needs to be on non-volatile storage. This is usually achieved by writing to a write-ahead log, which is useful for recovery as well.
Single & Multi-Object Operations
-
Do we need transactions for single-object operations?
- Yes, because you would still need a guarantee like isolation to ensure two different queries don’t read each other’s data till it’s committed. Like “dirty read”.
- Similarly, atomicity to rollback in case of failure.
- Like updating a single JSON object - fails in between, power failure do you have a combination of old/new data, etc?
-
Need for multi-object transactions
- Foreign key updates - Updating the table row, need to update another table.
- Secondary indexes - Need to be updated as well.
-
Handling errors and aborts
- Retrying an aborted transaction is a simple way of error handling. It’s perfect -
- Transaction succeeded but the network failed while trying to acknowledge a successful commit to the client. Retrying in that case is performed twice.
- Error due to overload - limit the number of retries, use exponential backoff, and handle overload-related errors differently from other errors.
- Transaction with side-effects outside the database like sending emails. Using a two-phase commit protocol can help here.
- Retrying an aborted transaction is a simple way of error handling. It’s perfect -
Weak Isolation Levels
If two transactions don’t touch the same data, they can safely run in parallel because neither depends on the other. Concurrency issues (race conditions) only come into play when one transaction reads data that is concurrently modified by another transaction, or when two transactions try to simultaneously modify the same data.
-
Dirty reads: One transaction reads another transaction’s uncommitted changes.
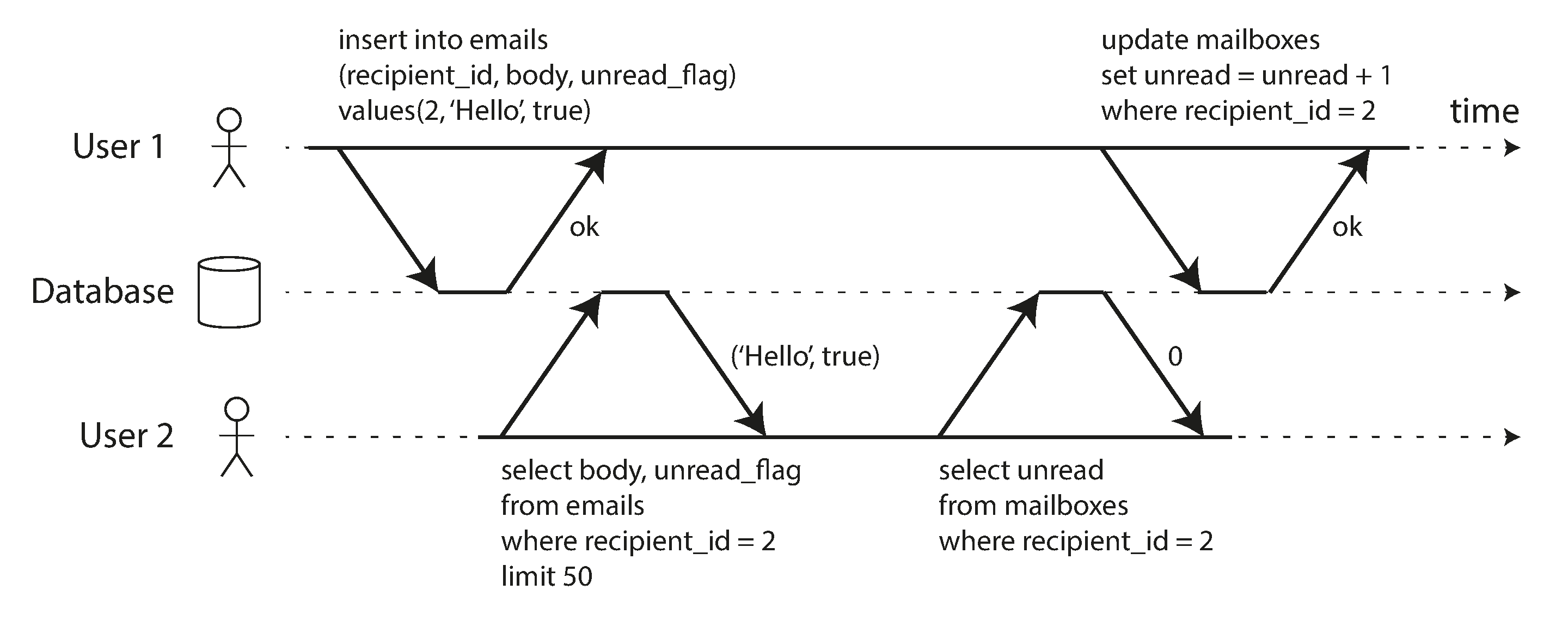
-
Dirty writes: One transaction overwrites data that another transaction has written, but not yet committed.
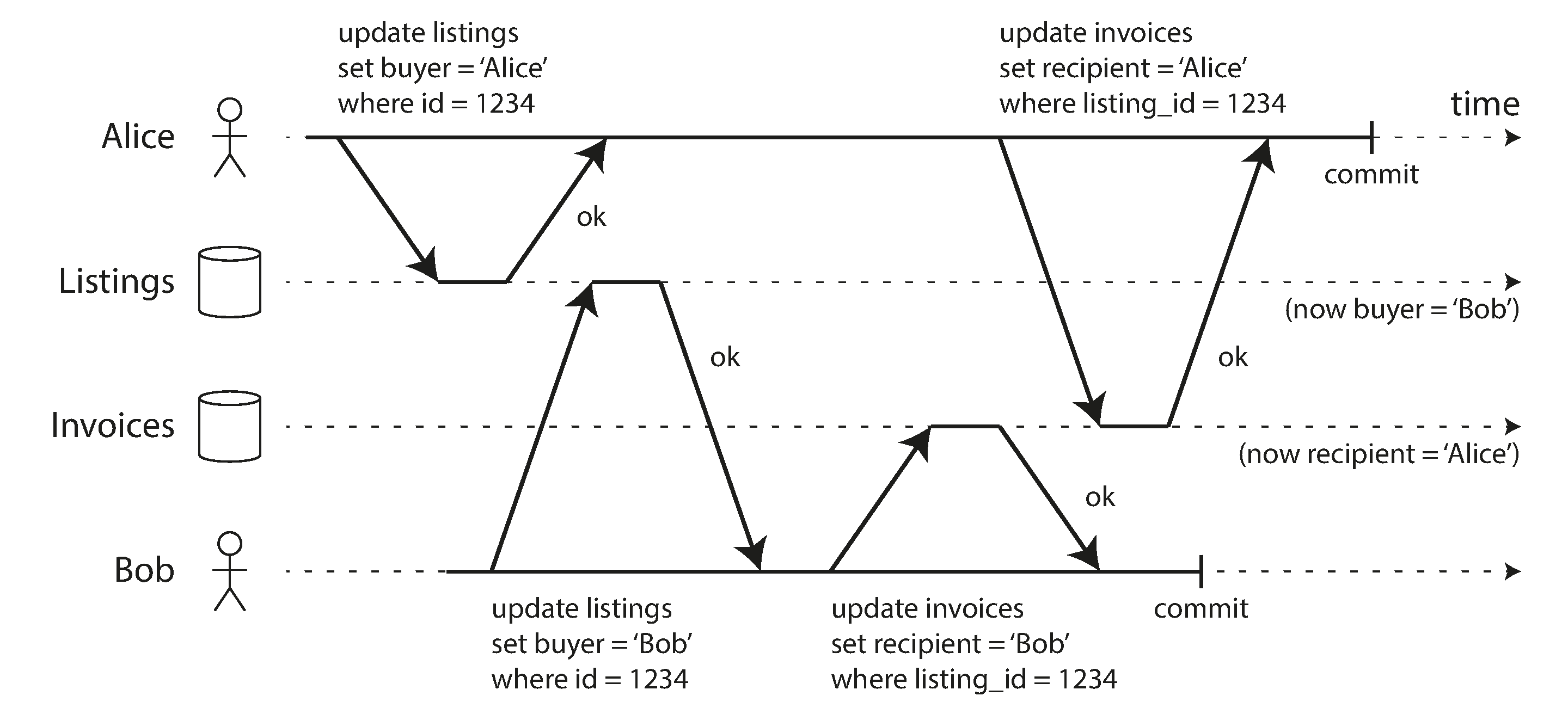
-
Read Committed: Provides two guarantees - “No dirty reads” and “No dirty writes”.
- To prevent dirty writes database uses row-level locks: When a transaction wants to modify a row, it must first acquire a lock on that row. It must then hold the lock until the transaction is committed or aborted. Only one transaction can hold the lock for any given row at a time.
- Similarly, we can have read locks to prevent dirty reads. But this doesn’t work well in practice due to potentially long-running write transactions forcing others to wait for a long time.
- The database remembers both the old committed value and the new value set by the transaction that holds the write lock. Other transactions read the old value until the transaction holding the write lock commits, at which point they read the new value.
-
Snapshot Isolation and Repeatable Read: Do we need another isolation level? Doesn’t “Read committed” work well for everything?
- Read Skew: Seeing different values for the same row at different times. Both are committed values hence valid under read committed.
Example of nonrepeatable read - Querying two different accounts between which money is transferred.
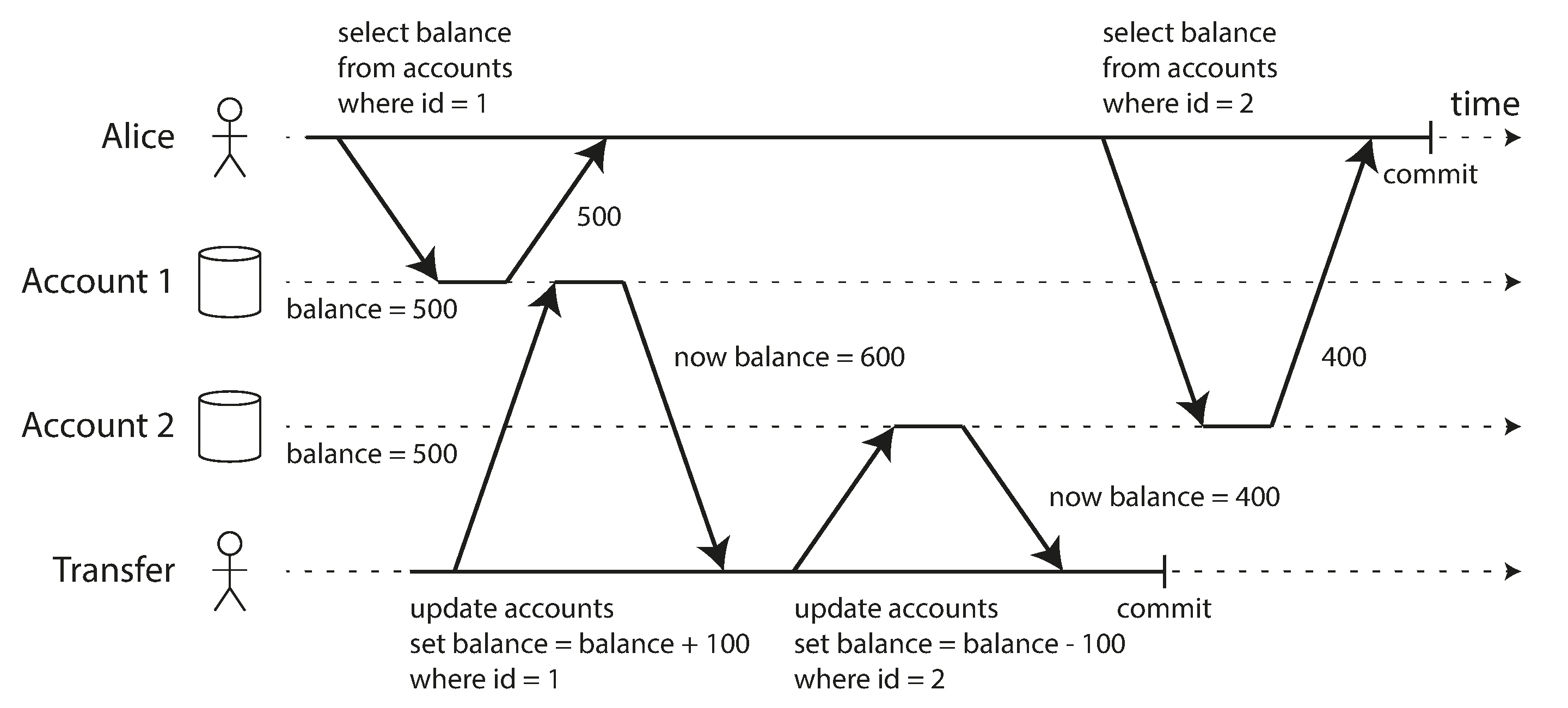 - The above can be an actual problem in case of backups. Writing to backup keeps happening and then the main database fails. The backup is restored and could potentially end up with an old version of some data since the backup hasn’t written the new data yet.
Snapshot isolation can solve this problem. Each transaction reads from a consistent snapshot of the database. This snapshot is taken at the beginning of the transaction. Even if the data is modified by another transaction, each transaction sees only the old data from that particular point in time. It is great for long-running, read-only queries such as backups and analytics.
- The above can be an actual problem in case of backups. Writing to backup keeps happening and then the main database fails. The backup is restored and could potentially end up with an old version of some data since the backup hasn’t written the new data yet.
Snapshot isolation can solve this problem. Each transaction reads from a consistent snapshot of the database. This snapshot is taken at the beginning of the transaction. Even if the data is modified by another transaction, each transaction sees only the old data from that particular point in time. It is great for long-running, read-only queries such as backups and analytics.- It uses write locks similar to read committed to prevent dirty writes. But for reads it uses a different approach. It doesn’t use read locks.
Reader never blocks writer and writer never blocks reader.
- Instead, it uses a technique called Multi-Version Concurrency Control (MVCC). It keeps multiple committed versions of an object. Each transaction reads from the version that was committed at the time the transaction started. This ensures that the transaction sees a consistent snapshot of the database.
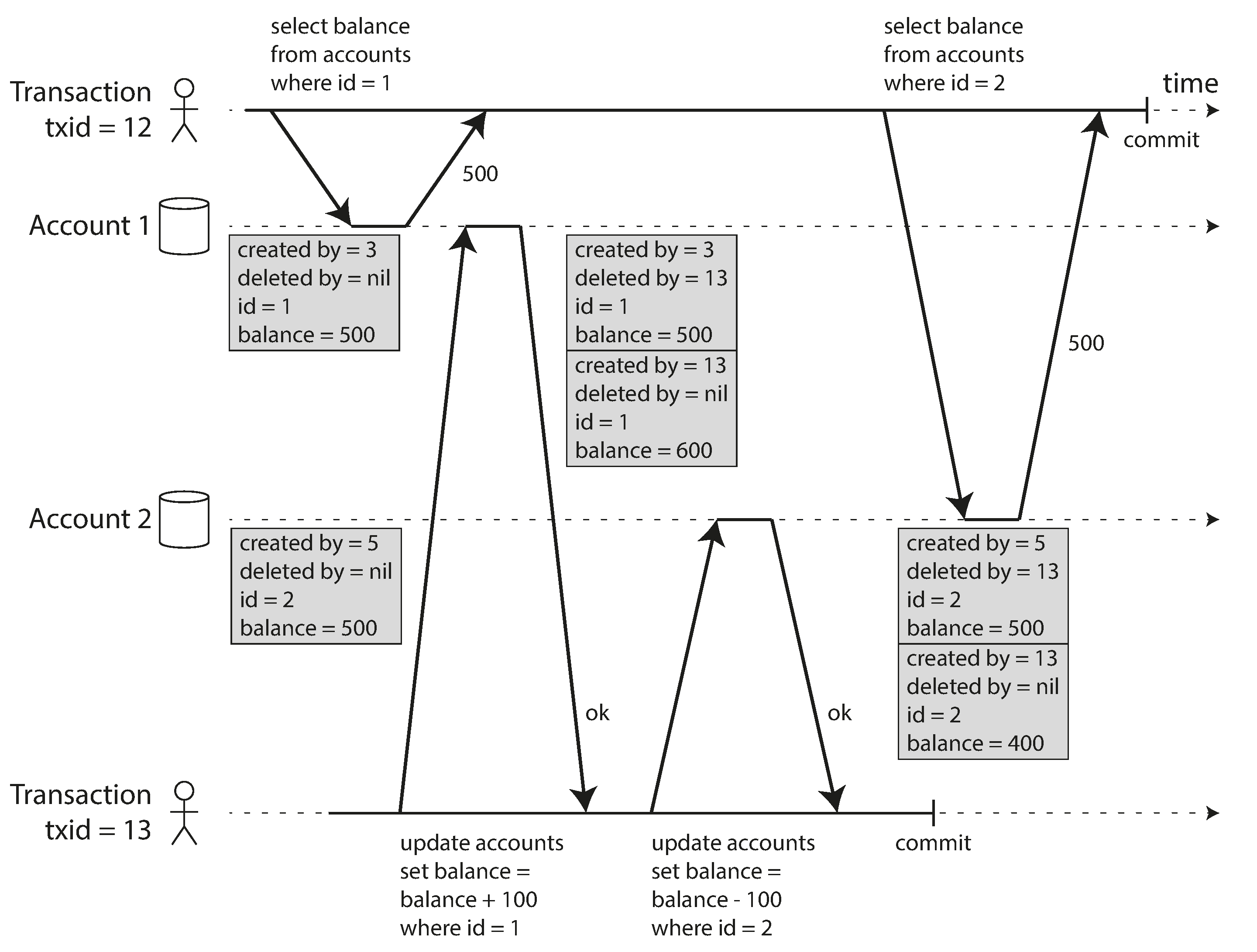
A long-running transaction may continue using a snapshot for a long time, continuing to read values that (from other transactions’ points of view) have long been overwritten or deleted. By never updating values in place but instead creating a new version every time a value is changed, the database can provide a consistent snapshot while incurring only a small overhead.
- Indexes - One approach used in CouchDB is to use an append-only/copy-on-write variant (B-trees) that doesn’t overwrite pages of the tree when they are updated, but instead creates a new copy of each modified page.
- Oracle calls it “serializable” and in PostgreSQL, MySQL it’s called “repeatable read”.
- Read Skew: Seeing different values for the same row at different times. Both are committed values hence valid under read committed.
-
Preventing Lost Updates
- Atomic write operations - Done by taking an exclusive lock on the object when it is read so that no other transaction can read it until the update has been applied - “Cursor Stability”. Example - “UPDATE … SET … WHERE …“.
- Explicit Locking - “FOR UPDATE” in SQL.
- Automatic lost update detection - PostgreSQL, Oracle and SQL Server provide this feature and abort offending transaction on detection.
- Compare-and-set - Avoid lost updates by allowing an update to happen only if the value has not changed since you last read it. IF the current value doesn’t match what you previously read, the update has no effect and the read-modify-write cycle must be retried.
- The last write wins (LWW) conflict resolution method is prone to lost updates. Unfortunately, it is the default in many replicated databases.
-
Write Skew and Phantoms
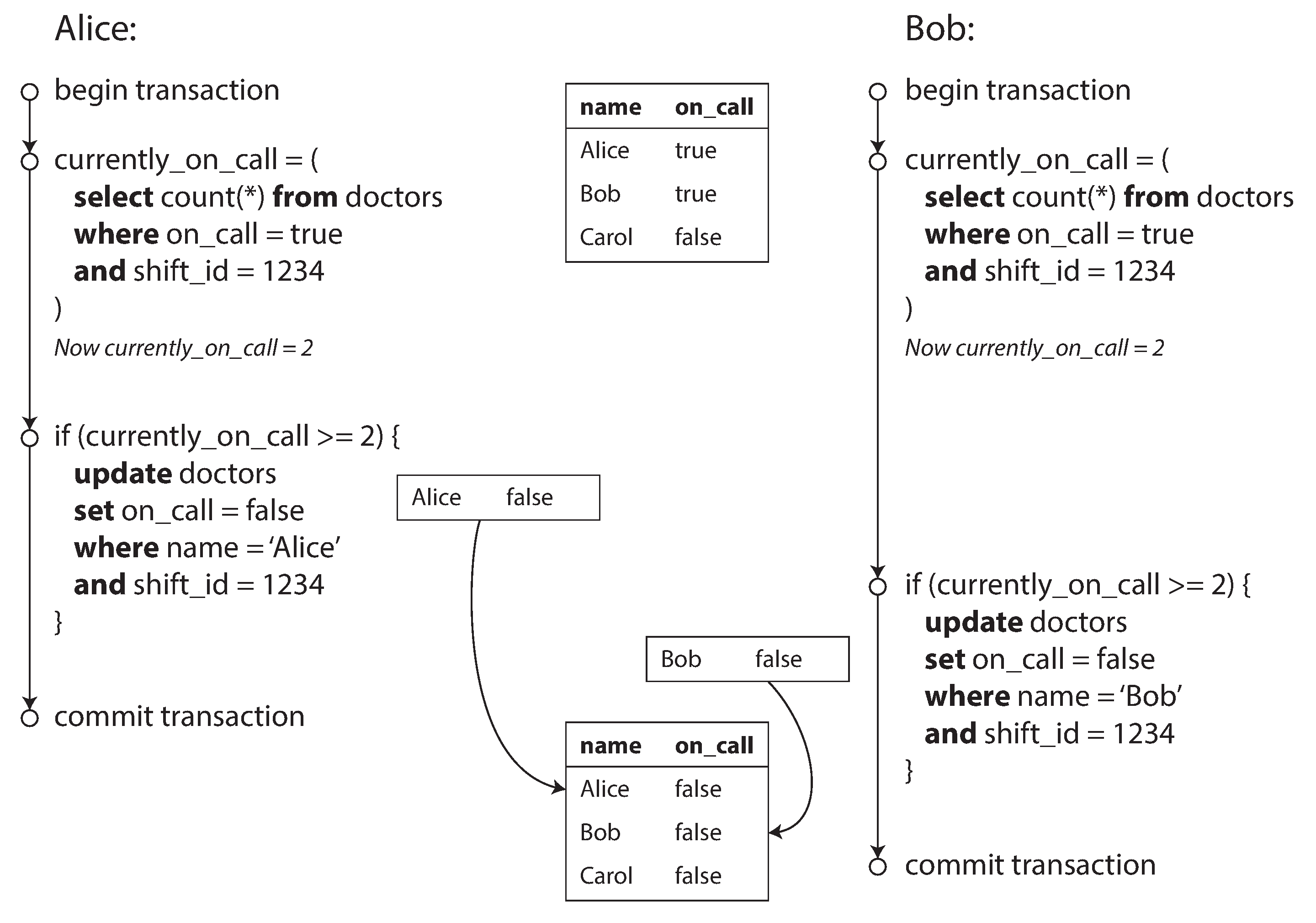
- Generalization of the lost update problem. It can occur if two transactions read the same objects and then update some of those objects (different transactions may update different objects). In the special case where different transactions update the same object, you get a dirty write or lost update anomaly (depending on the timing).
- For prevention
- Configure constraints, at times using triggers or materialized views.
- Explicitly lock the rows that the transaction depends on.
- More examples of write skew -
- Multiplayer game - Two players trying to move to the same location.
- Booking system
- Claiming a username in a system.
- Above examples check for the absence of rows matching some search condition, and the write adds a row matching the same condition. If the select query doesn’t return any rows, “SELECT FOR UPDATE” can’t attach locks to anything. This effect, where a write in one transaction changes the result of a search query in another transaction, is called a phantom.
- Snapshot isolation avoids phantoms in read-only queries but in read-write transactions, phantoms can lead to particularly tricky cases of write skew.
- Materializing conflicts - Basic idea is to introduce a table against which locks can be taken. In case of booking example this table could simply be a table with time slots and rooms. This approach turns a phantom into a lock conflict on concrete set of rows that exist in the database.
- But this can be a hard and error-prone to figure out how to materialize conflicts and it’s ugly to let a concurrency control mechanism leak into the application data model. Hence a serializable isolation level is a better choice.
Serializability
-
Strongest isolation level. It guarantees that even though transactions may run in parallel, the end result is the same as if they had run one after the other.
-
Actual Serial Execution
-
Simply just execute one transaction at a time, in serial order, on a single thread.
-
Before multi-threaded concurrency was thought essential to achieve good performance, but things have changed now.
- RAM became cheaper, leading to all data needed by a transaction can be in memory meaning faster execution. Since no need to fetch data from disk.
- OLTP transactions are usually short and only make a small number of reads and writes.
-
Encapsulating transactions in stored procedures
- Systems with single-threaded serial transaction processing don’t allow interactive multi-statement transactions. Instead, the application must submit entire transaction code to the database ahead of time, as a stored procedure.
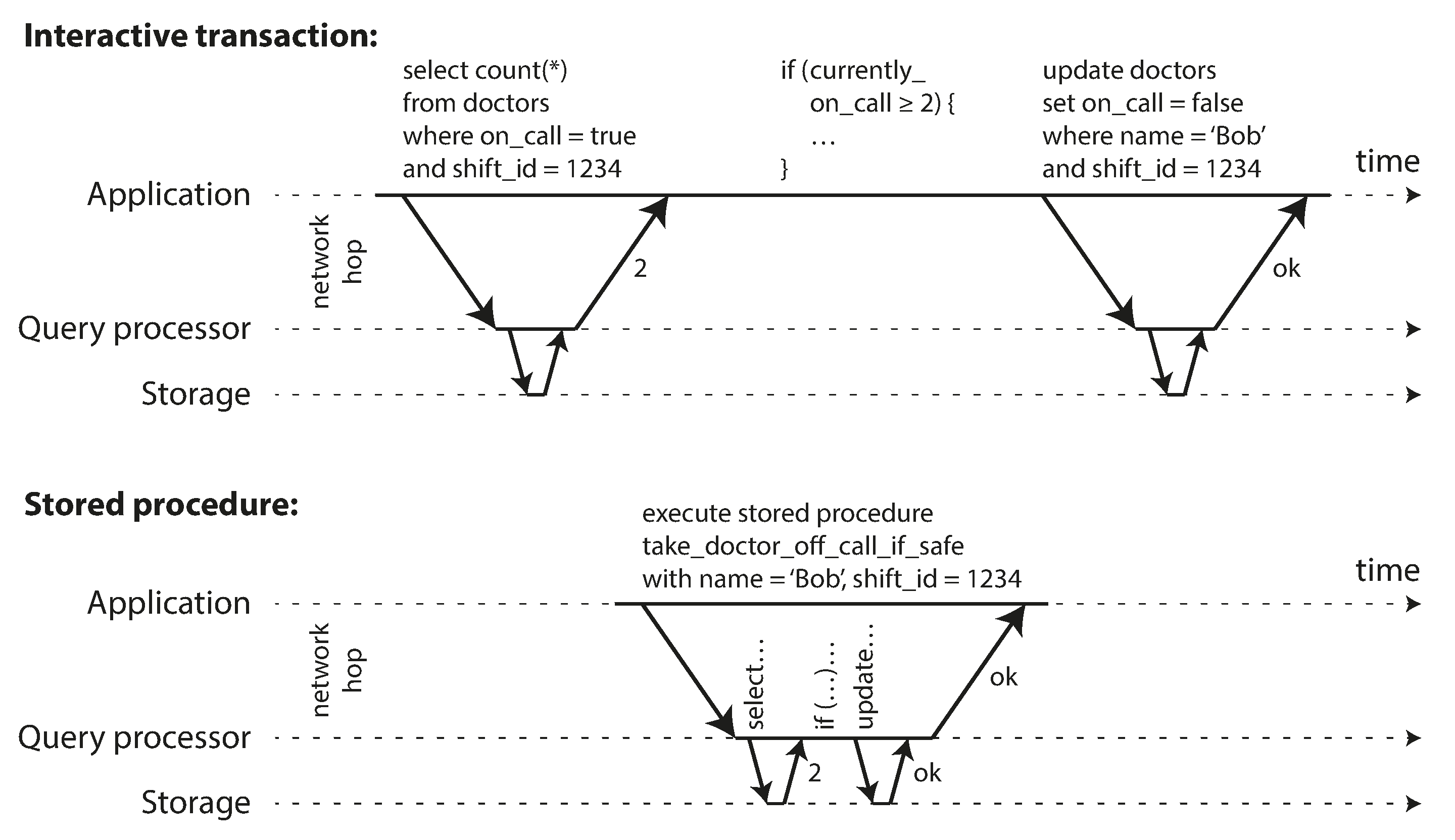
-
Partitioning
- If you can partition your data so that each transaction only needs to read and write data within a single partition, then each partition can have its own processing thread runnning independently from others.
- In this case, you can give each CPU core its own partition, which allows your transaction throughput to scale linearly with the number of CPU cores.
- Cross-partition transactions are possible, but there is a hard limit to the extent to which they can be used.
-
-
Two-Phase Locking (2PL)
- Several transactions are allowed to concurrently read the same object as long as nobody is writing to it. But as soon as anyone wants to write an object, exclusive access is required.
- Writers don’t just block other wrters; they also block readers and vice versa.
- Big downside and reason why it’s not used since 1970s is performance: transaction throughput and response times of queries are significantly worse than with weaker isolation levels.
- To prevent Phantoms, two ways exist -
- Predicate locks
- It works similarly to the shared/exclusive lock, but rather than belonging to a particular object, it belongs to all objects that match some search condition.
- It applies even to objects that do not yet exist in the database, but which might be added in the future(phantoms).
- Index-range locks
- It’s a generalization of the predicate lock. Rather than locking all objects that match a search condition, it locks all objects within a range of values in an index.
- They are not as precise as predicate locks would be (they may lock a bigger range of objects than is strictly necessary to maintain serializability), but since they have much lower overheads, they are good compromise.
- Predicate locks
-
Serializable Snapshot Isolation (SSI)
-
It provides full serializability, but has only a small performance cost compared to snapshot isolation. SSI is fairly new, came out in 2008.
-
PostgreSQL has it as of version 9.1.
-
Its a optimistic concurrency control technique. Instead of being pessimistic like 2PL.
-
It allows transactions to continue in hope that everything will turn out fine. When a transaction wants to commit, it checks whether isolation was violated or not. If yes, the transaction is aborted and has to be retried.
-
On top of snapshot isolation, SSI adds an algorithm for detecting serialization conflicts among writes and determining which transactions to abort.
-
Decision based on an outdated premise
- In order to provide serializable isolation, the database must detect situations in which a transaction may have acted on an outdated premise and abort the transaction in that case.
- How does the database know if a query result might have changed?
- Detecting reads of a stale MVCC object version (uncommitted write occurred before the read)
- Detecting writes that affect prior reads (the write occurs after the read)
-
Detecting stale MVCC reads
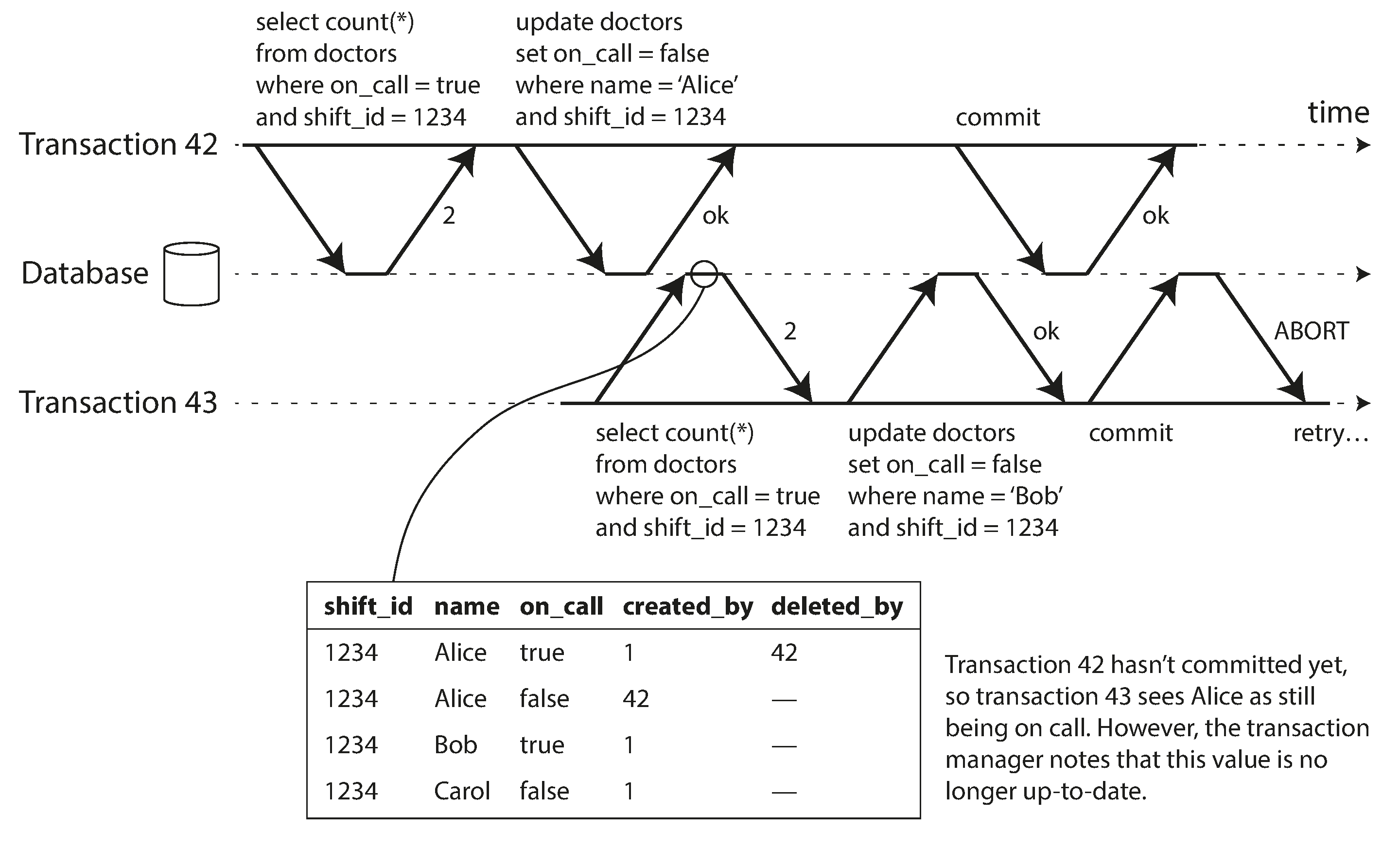
- Transaction 42 may yet abort or may still be uncommitted at the time when transaction is committed, and so the read may turn out not to have been stale after all. By avoiding unnecessary aborts, SSI preserves snapshot isolation’s support for long-running reads from a consistent snapshot.
-
Detecting writes that affect prior reads
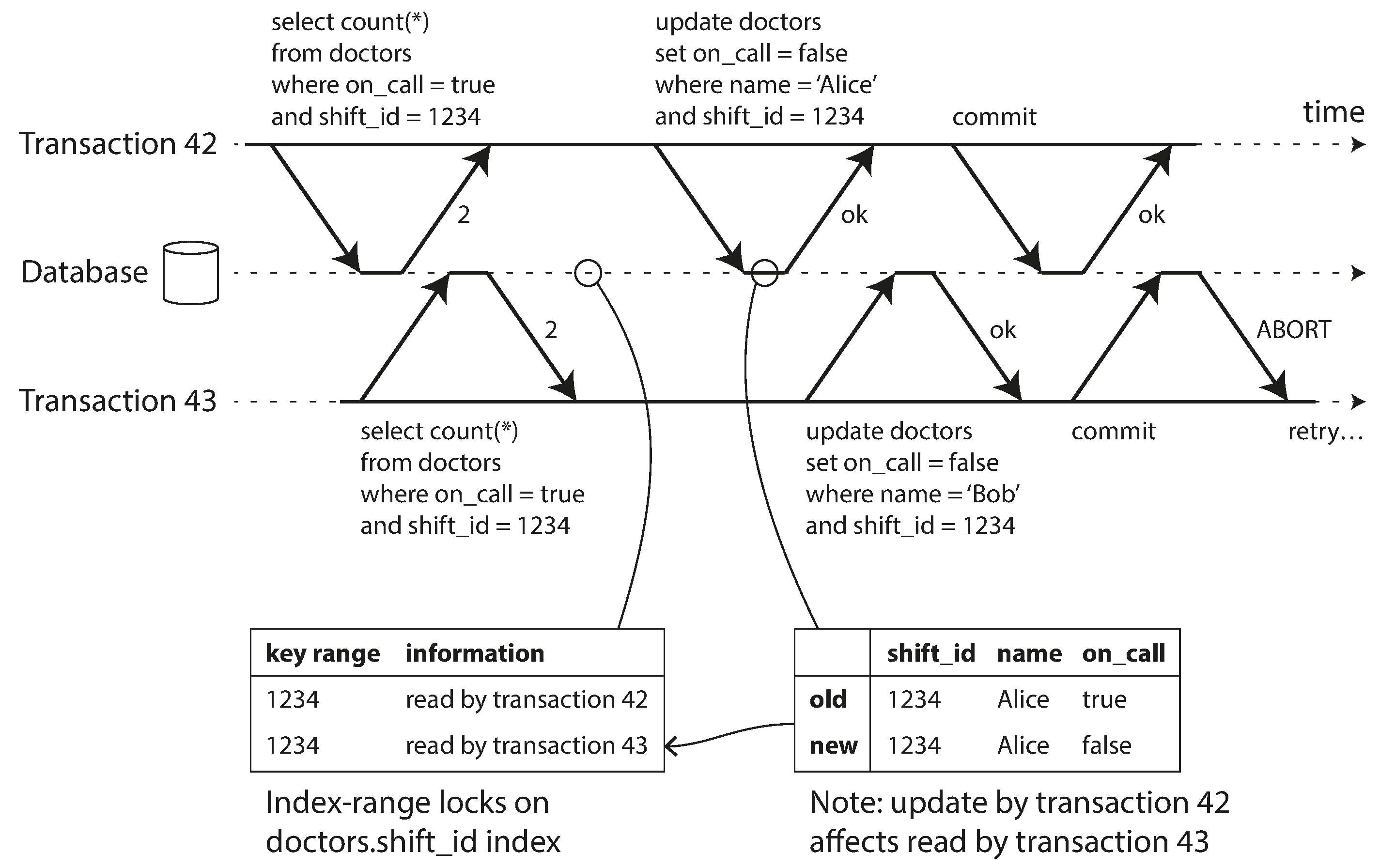
- Information related to which transaction read the data, needs to be kept only for a while: after a transaction has finished(committed or aborted), and all concurrent transactions have finished, the database can forget what data it read.
- When a transaction writes to the database, it must look iin the indexes for any other transactions that have recently read the affected data.
- This process is similar to acquiring a write lock on the affected key range, but rather than blocking until the readers have committed, the lock acts as a tripwire: it simply notifies the transactions that the data they read may no longer be up to date.
-
Performance of SSI
- Compared to 2PL, the big advantage of SSI is that one transaction doesn’t need to block waiting for locks held by another transaction.
- Compared to serial execution, SSI is not limited to the throughput of a single CPU core: FoundationDB, distributes the detection of serialization conflicts across multiple machines, allowing it to scale to very high throughput.
-