Faults and Partial Failures
- Single computer are deterministic, meaning the same operation always produces the same result unless there is a hardware fault.
- With distributed systems that isn’t the case. They are connected via network.
- At times parts of the systems are broken un some unpredictable way, even though other parts of the system are working fine. This is called partial failure. They are non-deterministic in nature.
In my limited experience, I have dealt with long-lived network partitions in a single data center, PDU [Power Distribution Unit] failures, and network switch failures, accidental power cycles of whole racks, whole-DC backbone failures, whole-DC power failures, and a hypoglycemic driver smashing his Ford pickup truck into a DC’s HVAC system. And I’m not even an ops guy.
- Supercomputer is more like a single-node computer in the way it deals with partial faulure. It escalates that into total failure, just let everything crash (like kernal panic on a single machine).
- Distributed systems need to be equipped to deal with partial failures by having fault-tolerant mechanisms in place. Building a reliable system from unreliable components.
- Error-correcting codes allows data to be transmitted accurately across a communication channel that occasionally gets some bits wrong, for example due to radio interference on a wireless network.
- IP is unreliable, TCP provides more reliable transport layer on top of IP. It ensures missing packets are retransmitted, duplicates are discarded, and packets are reassembled in the correct order.
Unreliable Networks
-
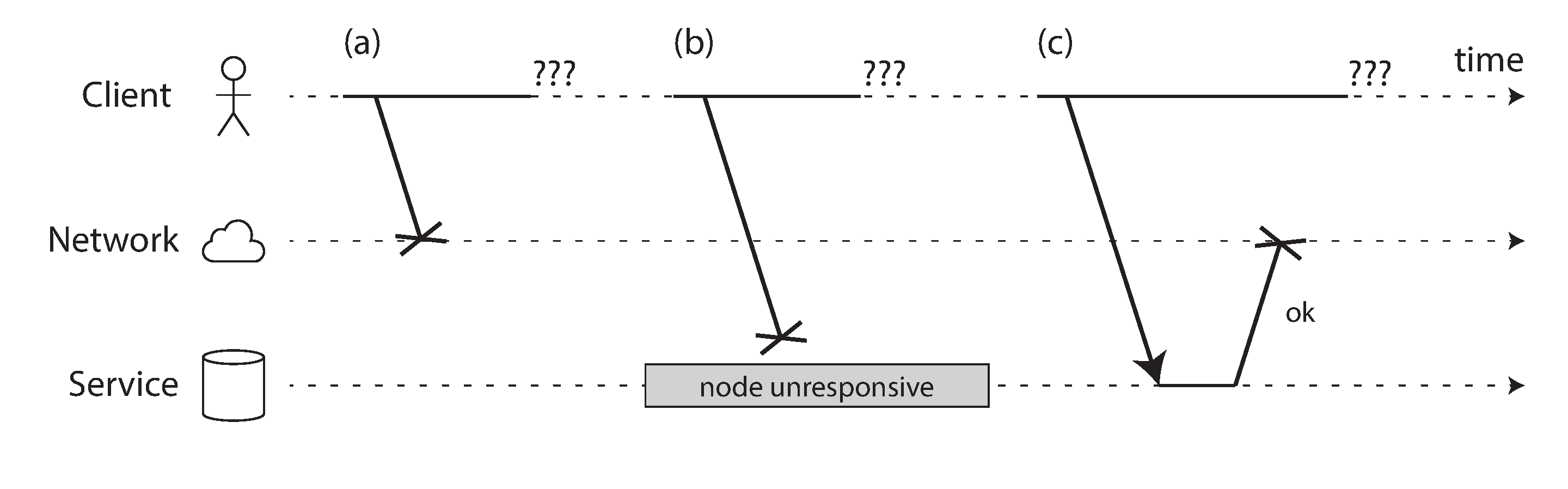
If you send a request and expect a response, many things could go wrong. To name a few -
- The request maybe waiting in a queue and will be delivered later (perhaps the network or the recipient is overloaded).
- The remote node may have temporarily stopped responding(like garbage collection pause), but it will start responding again after a while.
-
If you send a request to another node and don’t receive a response, it is impossible to tell why.
-
The usual way of handling this issue is a timeout: after some time you give up waiting and assume that the response is not coming. However, when a timeout occures, you still don’t know whether the remote node got your request or not(and if the request is still queued somewhere, it may still be delivered to the recipient, even if the sender has given up).
-
Network Partitions - When one part of the network is cut off from the rest due to a network fault, that is sometimes called a network partition or netsplit.
-
Handling network faults doesn’t necessarily mean tolerating them: if your network is normally fairly reliable, a valid approach may be to simply show an error message to users while your network is experiencing problems.
-
Detecting Faults
- Many systems need to automatically detect fault nodes. Like load balancer, distributed database with single-leader replication, etc.
- Again due to uncertainty of network, it is difficult to say if a node is working or not(maybe just slow). Though in some cases, we get explicit feedback telling something is not working -
- No process is listening on the destination port(process crashed), the OS will helpfully close or refuse TCP connections by sending a RST or FIN packet in reply. Though, if the node crashed while it was handling your request, you have no way of knowing how much data was actually processed by the remote node.
- If a node process crashed but the node’s OS is still running, a script can notify other nodes about the crash so that another node can take over quickly without having to wait for a timeout to expire. HBase does this.
- If you have access to the management interface of the network switches in your datacenter, you can query them to detect link failures at a hardware level(e.g., if remote machine is powered down).
- If a router is sure that the IP address you’re trying to connect to is unreachable, it may reply to you with an ICMP Destination Unreachable message.
-
Timeouts and Unbounded Delays
- A long timeout means a long wait until a node is declared dead (and during this time, users may have to wait or see error messages). A short timeout detects faults faster, but carries a higher risk of incorrectly declaring a node dead when in fact it has only suffered a temporary slowdown.
- Prematurely declaring a node dead is problematic: if the node is actually alive and in the middle of performing some action(for example, sending an email), and another node takes over, the action may end up being performed twice.
- Network congestion and queueing
- Like when a packet reaches the destination machine, if all CPU cores are currently busy, the incoming request from the network is queued by the OS until the application is ready to handle it.
- TCP performs flow control(congestion avoidance or back-pressure) in which a node limits its own rate of sending in order to avoid overloading a network link or the receiving node.
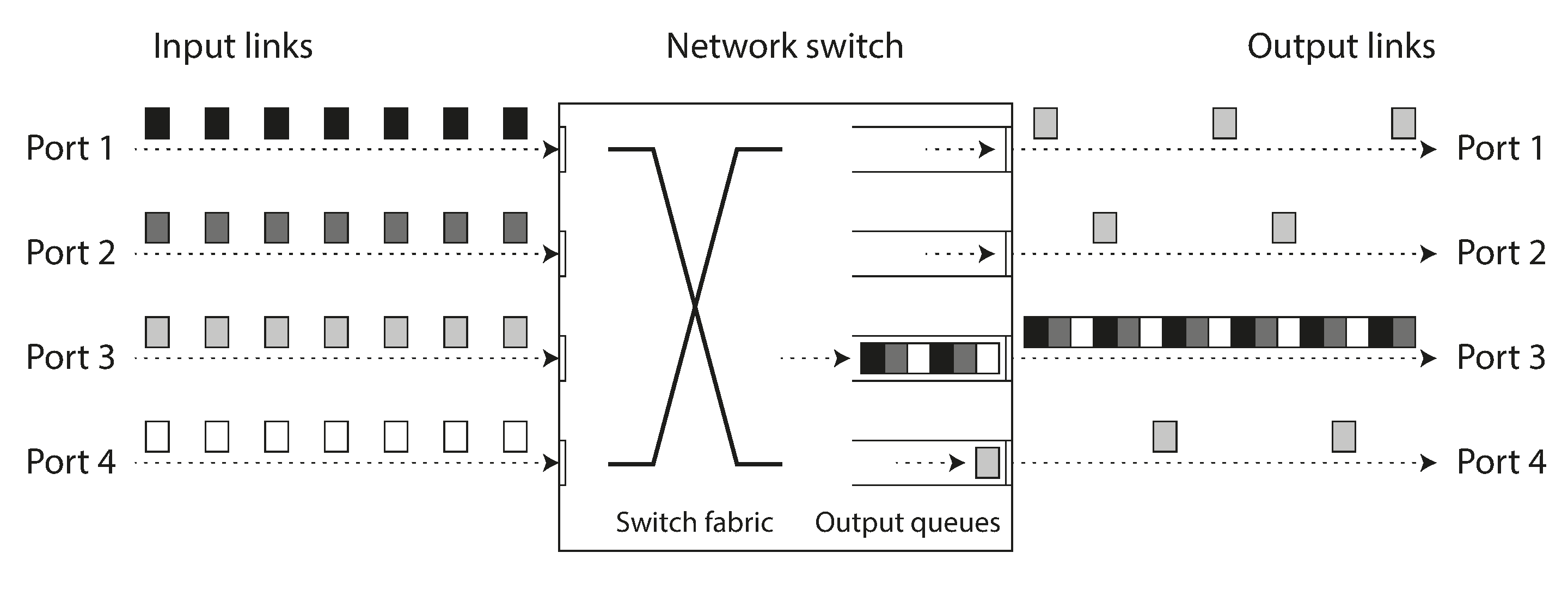
- Although the application does not see the packet loss and retransmission, it does see the resulting delay(waiting for the timeout to expire and then waiting for retransmitted packet to be acknowledged).
- UDP doesn’t perform flow control and doesn’t retransmit lost packets, it avoids some of the reasons for variable network delays. It’s a good choice for real-time applications like VoIP, video chat, and online gaming, where it’s better to drop a few packets than to have long delays.
- Rather than using configured constant timeouts, systems can continually measure response times and their variability(jitter), and automatically adjust timeouts according to the observed response time distribution. This can be done with Phi Accrual Failure Detector used in Akka and Cassandra. TCP retransmission timeouts also work similarly.
- Synchronous Versus Asynchronous Networks
- When you make a call over the telephone network, it establishes a circuit: a fixed, guaranteed amount of bandwidth is allocated for the call, along the entire route between the two callers. This circuit remains in place until the call ends. For example, an ISDN network runs a fixed rate of 4000 frames per second. When a call is established, it is allocated 16 bits of space within each frame(in each direction). Thus, for the duration of the call, each side is guaranteed to be able to send exactly 16 bits of audio data every 250 microseconds.
- The above kind of network is synchronous: even as data passes through several routers, it does not suffer from queueing, because the 16 bits of space for the call have already been reserved in the next hop of the network. And because there is no queueing, the maximum end-to-end latency of the network is fixed. We call this a bounded delay.
- Note: ISDN itself is now mostly phased out and newer technologies use packet switching instead of circuit switching. Circuit switching is only used as a fallback in the newer systems.
- Circuit-Switched Fallback (CSFB) in Mobile Networks: In 4G LTE networks, Circuit-Switched Fallback (CSFB) allows devices to switch to older 2G or 3G circuit-switched networks when making a voice call if the VoLTE (Voice over LTE) capability is unavailable. However, 5G aims to operate fully on packet-switched networks, eliminating the need for circuit-switched fallback.
- With careful use of quality of service (QoS, prioritization and scheduling of packets) and admission control (rate-limiting senders), it is possible to emulate circuit switching on packet networks, or provide statistically bounded delay.
- Packet switching is optimized for bursty traffic. TCP dynamically adapts the rate of data transfer to the available network capacity.
- Internet shares network bandwidth dynamically. Senders push and jostle with each other to get their packets over the wire as quickly as possible, and the network switches decide which packet to send(i.e., the bandwidth allocation) from one moment to the next. This approach has the downside of queueing, but the advantage is that it maximizes utilization of the wire. The wire has a fixed cost, so if you utilize it better, each byte you send over the wire is cheaper.
Unreliable Clocks
- In a distributed system, each machine typically has its own clock, usually a quartz crystal oscillator. These clocks are not perfect: they drift apart from each other, and they can sometimes jump forward or backward in time.
- It is possible to synchronize clocks to some degree using the Network Time Protocol (NTP), which allows computer clock to be adjusted according to time reported by a group of servers. The servers in turn get their time from a more accurate time source, such as a GPS receiver.
- Time-of-day clocks - It returns the current date and time according to some calendar. Usually, it is synchronized with NTP. Jumping of the clock can happen due to leap seconds, daylight saving time, or manual adjustments.
- Monotonic clocks - Suitable for measuring a duration(time interval), such as a timeout or a service’s response time. They are guaranteed to always move forward (whereas a time-of-day clock may jump back in time).
- Clock Synchronization and Accuracy: Our methods of getting a clock to tell the correct time aren’t nearly as reliable or accurate. A few examples -
- Quartz clock can drift due to temperature of the machine.
- If computer’s clock differs too much from an NTP server, it may refuse to synchronize, or local clock will be forcibly reset.
- Accidentally firewalled off from the NTP servers.
- NTP synchronization can only be as good as the network delay.
- Leap seconds result in a minute that is 59 seconds or 61 seconds long, which messes up timing assumptions in systems that are not designed with leap seconds in mind.
- Timestamps for ordering events
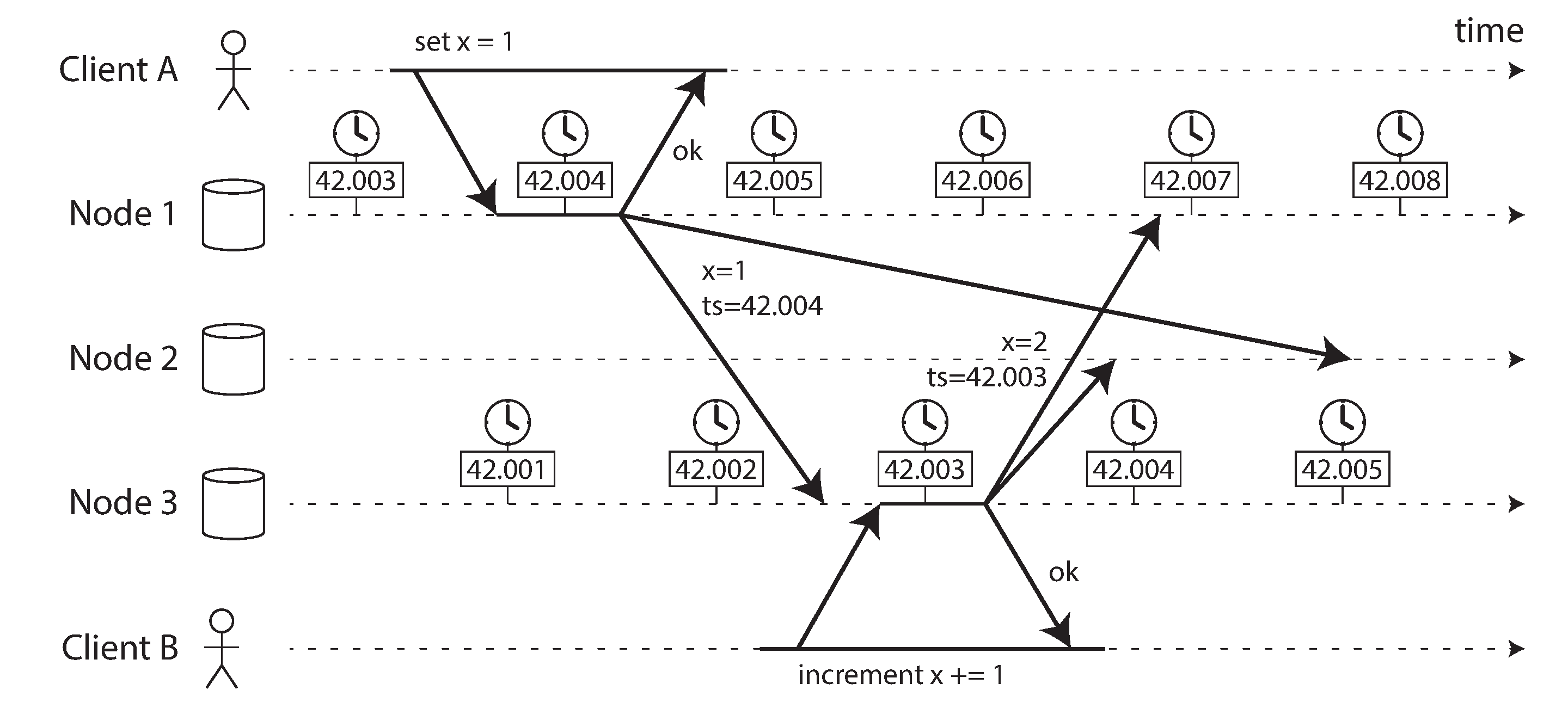
- It’s important to be aware that the definition of “recent” depends on a local time-of-day clock, which may well be incorrect. Even with tightly NTP-synchronized clocks, you could send a packet at timestamp 100ms(according to sender’s clock) and have it arrive at timestamp 99ms(according to receiver’s clock)- so it appears as though the packet arrived before it was sent, which is impossible.
- Logical clocks are based on incrementing counters. They do not measure the time of day or the number of seconds elapsed, only the relative ordering of events(whether one event happenened before or after another).
- Google’s TrueTime API, explicitly reports the confidence interbal on the local clock. When you ask it for the current time, you get back two values:
[earliest, latest], which are theearliest possibleand thelatest possibletimestamp. - Synchronized clocks for global snapshots
- The most common implementation of snapshot isolation requires a monotonically increasing transaction ID. If a write happened later than the snapshot (i.e., the write has a greater transaction ID than the snapshot), that write is invisible to the snapshot transaction. On a single-node database, a simple counter is sufficient for generating transaction IDs.
- In order to ensure that transaction timestamps reflect causality, Spanner deliberately waits for the length of the confidence interval before committing a read-write transaction.
- I want to understand the logical clocks a bit better and how CockroachDB does this. Planning to read the Time, Clocks, and the Ordering of Events in a Distributed System paper by Leslie Lamport. Additionally this lecture by Martin Kleppmann. This blog by CockroachDB.
- Process Pauses
- Leader obtains lease from the other nodes for a certain period of time. Now if during execution of the code which checks the lease validity and making of the request there is a unexpected pause in the execution of the program. In that case, it’s likely that the lease will have expired by the time the request is processedm and another ndoe has already taken over as the leader.
- Possible reasons for such long pauses -
- Garbage collection
- In virtualized environments, a virtual machine can be suspended (pausing the execution of all processes and saving the contents of memory to disk) and resumed(restoring the contents to memory and continuing execution).
- Closing of laptop lid.
- If the OS is configured to allow swapping to disk(paging), a simple memory access may result in a page fault that requires a page from disk to be loaded into memory. The thread is paused while this slow I/O operation is performed. In extreme circumstances, the OS may spend most of its time swapping pages in and out of memory, getting little actual work done(this is known as thrashing).
Knowledge, Truth, and Lies
- A node cannot necessarily trust its own judgement of a situation. A distributed system cannot exclusively rely on a single node, because a node may fail at any time, potentially leaving the system stuck and unable to recover.
- Distributed algorithms rely on quorum, that is, voting among nodes: decisions require some minimum number of votes from several nodes in order to reduce the dependence on any one particular node.
- The leader and the lock
- System requires there to be only one of some thing -
- Single leader for a database partition, to avoid split brain.
- One transaction or client is allowed to hold the lock on a particular resource.
- Incorrect implementation of distributed lock -
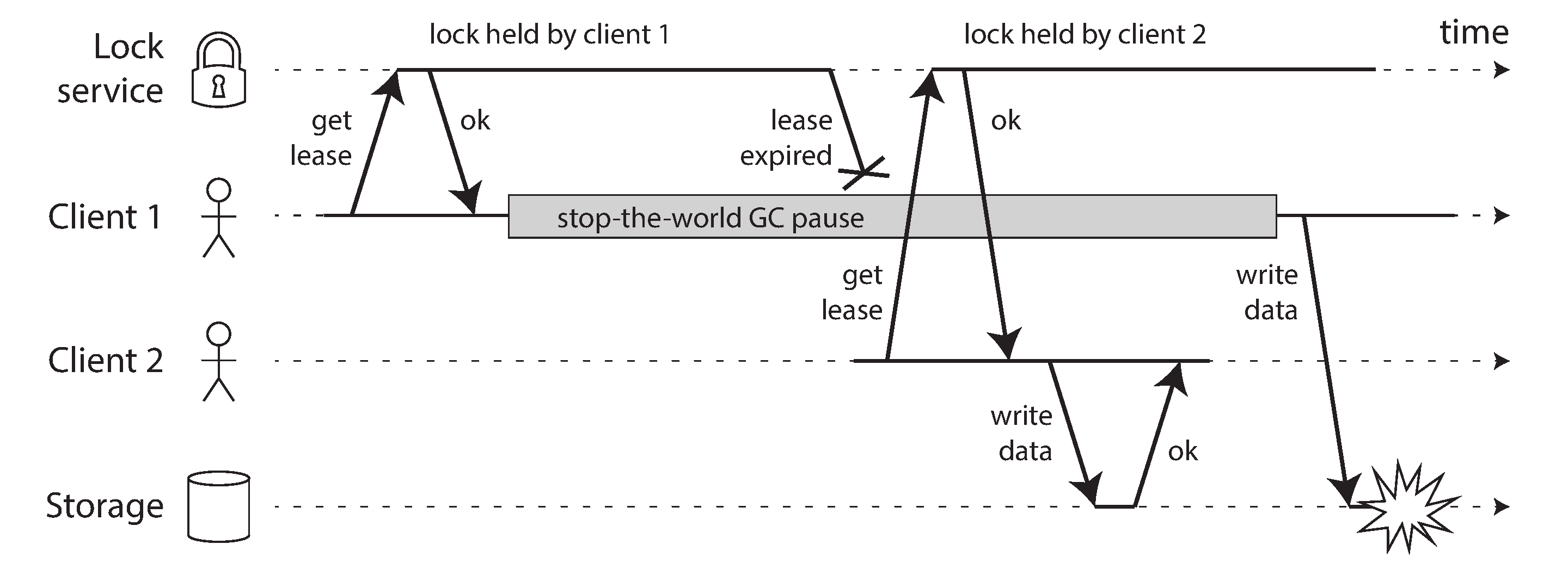
- Simple technique to avoid the above problem is to use something called as fencing.
- Every time the lock server grants a lock or lease, it also return a fencing token, which is a number that increases every time a lock is granted. We can then require that every time a client sends a write request to the storage service, it must include its current fencing token.
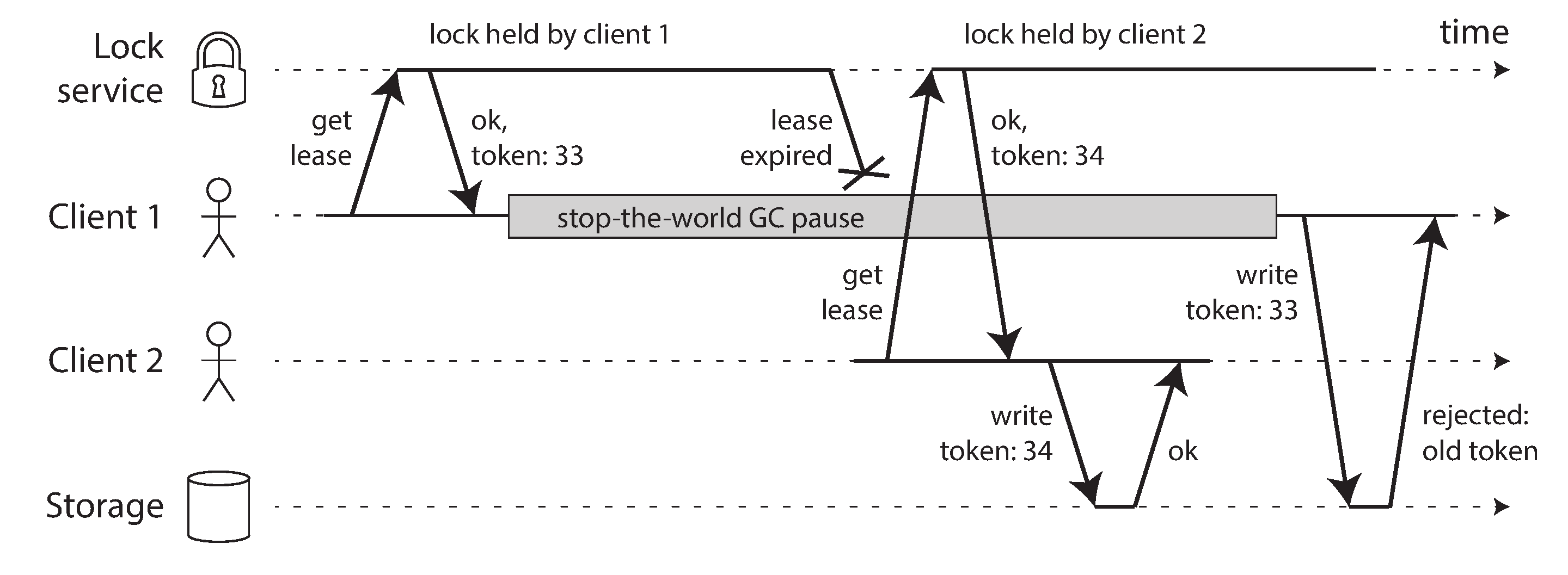
- System requires there to be only one of some thing -
- Byzantine Faults
- Fencing tokens can’t protect when there is possibility of a node lying.
- For example, if a node may claim to have received a particular message when in fact it didn’t. Such a behavior is known as a Byzantine fault, and the problem of reaching consensus in this untrusting environment is known as the Byzantine Generals Problem, lecture.
- Flight control system, peer-to-peer networks like Bitcoin and blockchains. Need to be Byzantine fault-tolerant.
- System Model
- With regard to timing assumptions -
- Synchronous model - It assumes bounded network delay, bounded process pauses, and bounded clock error. This does not imply exactly synchronised clocks or zero network delay; it just means you know that network delay, pauses, and clock drift will never exceed some fixed upper bound.
- Partially synchronous model - It assumes that the system behaves like a synchronous system most of the time, but occasionally has unbounded delay or other problems. This is a more realistic model of real-world systems.
- Asynchronous model - It makes no timing assumptions at all. It does not even have a clock.
- Besides timing issues, we have to consider node failures -
- Crash-stop failures - Node stops abruptly and does not recover.
- Crash-recovery failures - Node stops abruptly but may recover after unknown time.
- Byzantine (arbitrary) failures - Nodes may do absolutely anything, including trying to trick and deceive other nodes.
- With regard to timing assumptions -
- Correctness of an algorithm
- Properties we want of a distributed algorithm to define what it means to be correct. For example, generating fencing tokens for a lock -
- Uniqueness
- Monotonic sequence
- Availability
- Safety and liveness properties -
- Safety - Nothing bad happens. If a safety property is violated, we can point at a particular point in time at which it was broken.
- Liveness - Something good eventually happens. It may not hold at some point in time, but there is always hope that it may be satisfied in the future. Example - sending of request, receiving the response later.
- The definition of the partially synchronous model requires that eventually the system returns to a synchronous state - that is, any period of network interruption lasts only for a finite duration and is then repaired.
- Properties we want of a distributed algorithm to define what it means to be correct. For example, generating fencing tokens for a lock -